publications
publications by categories in reversed chronological order.
2025
- ICML
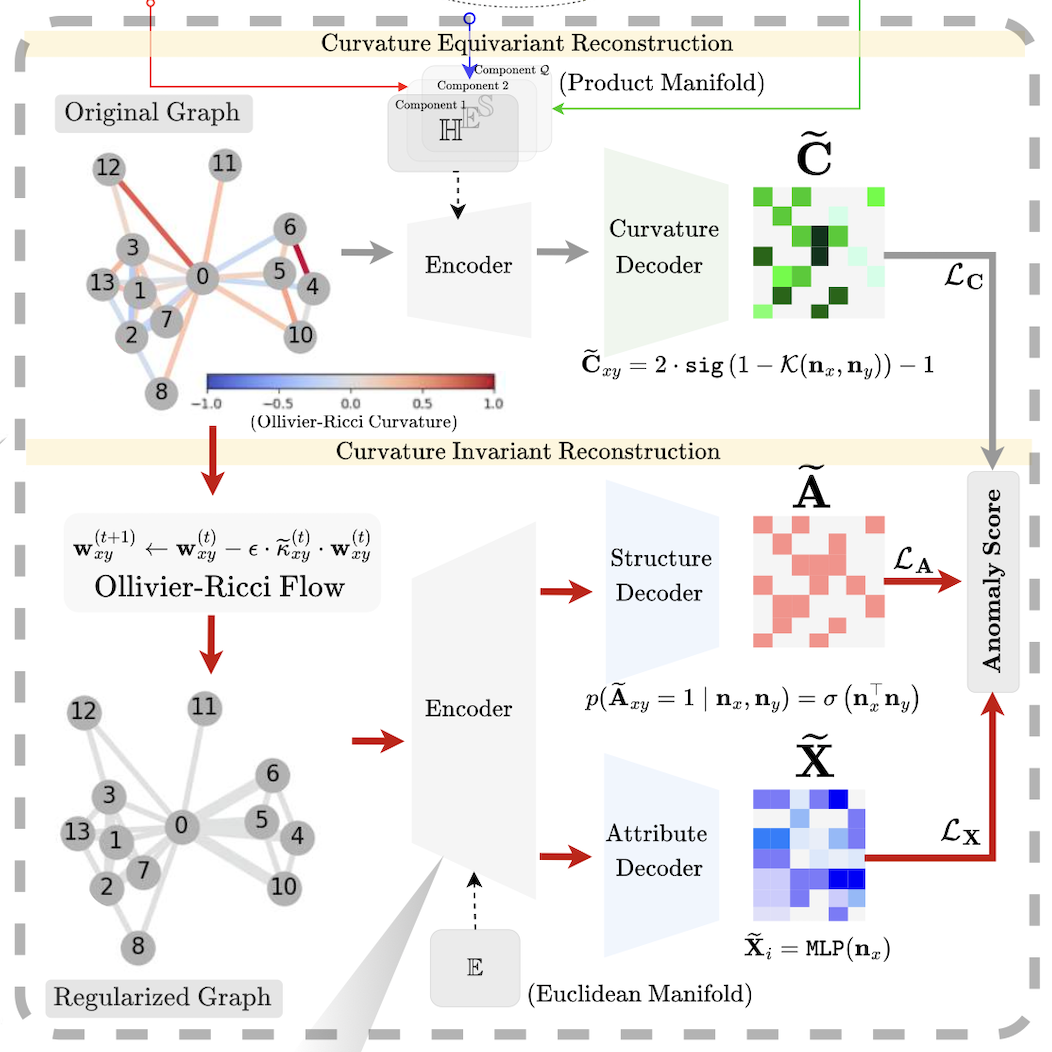 CurvGAD: Leveraging Curvature for Enhanced Graph Anomaly DetectionKarish Grover, Geoffrey J. Gordon, and Christos FaloutsosInternational Conference on Machine Learning 2025
CurvGAD: Leveraging Curvature for Enhanced Graph Anomaly DetectionKarish Grover, Geoffrey J. Gordon, and Christos FaloutsosInternational Conference on Machine Learning 2025Does the intrinsic curvature of complex networks hold the key to unveiling graph anomalies that conventional approaches overlook? Reconstruction-based graph anomaly detection (GAD) methods overlook such geometric outliers, focusing only on structural and attribute-level anomalies. To this end, we propose CurvGAD - a mixed-curvature graph autoencoder that introduces the notion of curvature-based geometric anomalies. CurvGAD introduces two parallel pipelines for enhanced anomaly interpretability: (1) Curvature-equivariant geometry reconstruction, which focuses exclusively on reconstructing the edge curvatures using a mixed-curvature, Riemannian encoder and Gaussian kernel-based decoder; and (2) Curvature-invariant structure and attribute reconstruction, which decouples structural and attribute anomalies from geometric irregularities by regularizing graph curvature under discrete Ollivier-Ricci flow, thereby isolating the non-geometric anomalies. By leveraging curvature, CurvGAD refines the existing anomaly classifications and identifies new curvature-driven anomalies. Extensive experimentation over 10 real-world datasets (both homophilic and heterophilic) demonstrates an improvement of up to 6.5% over state-of-the-art GAD methods.
- ICLR
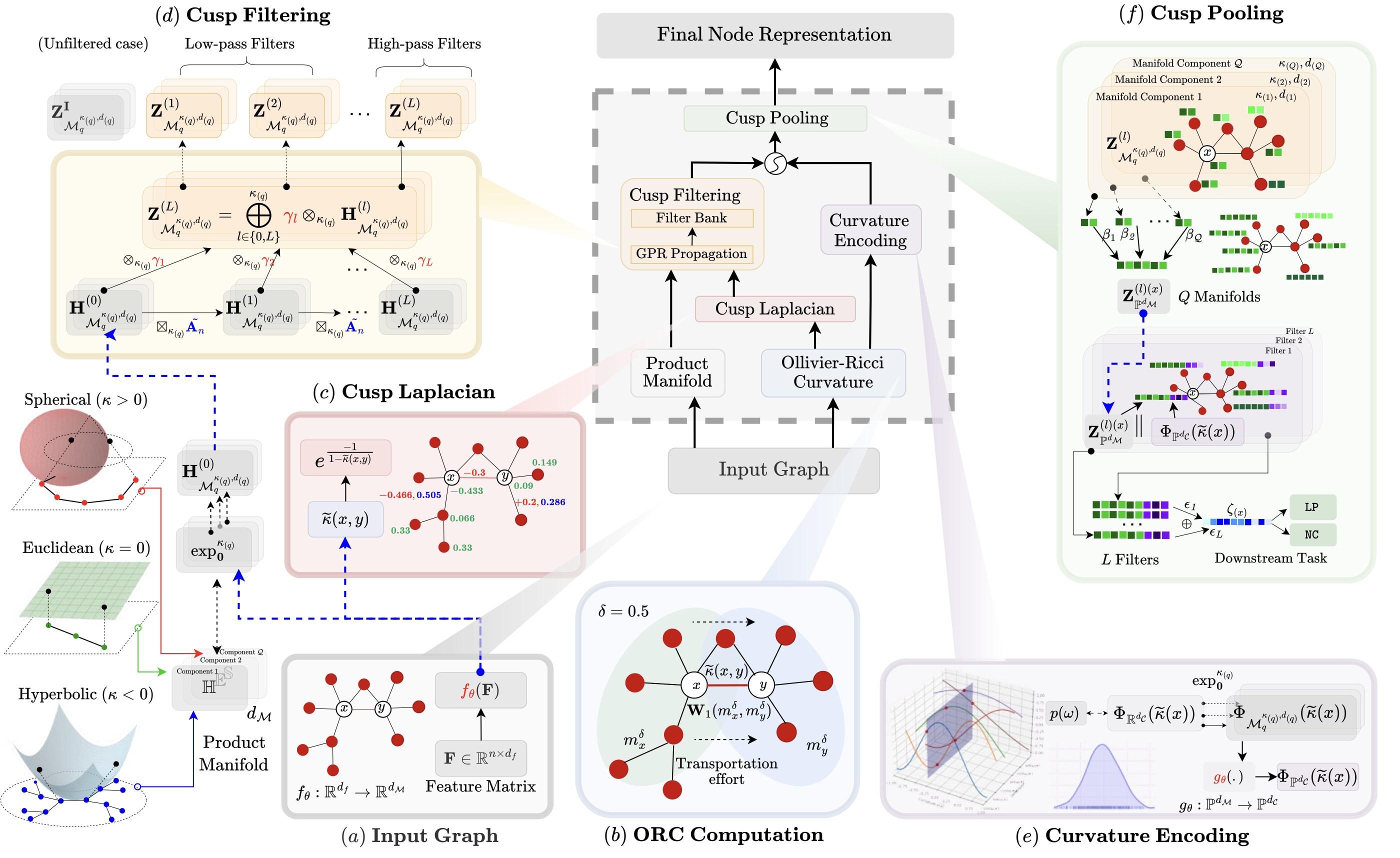 Spectro-Riemannian Graph Neural NetworksKarish Grover, Haiyang Yu, Xiang Song, Qi Zhu, and 3 more authorsInternational Conference on Learning Representations 2025
Spectro-Riemannian Graph Neural NetworksKarish Grover, Haiyang Yu, Xiang Song, Qi Zhu, and 3 more authorsInternational Conference on Learning Representations 2025Can integrating spectral and curvature signals unlock new potential in graph representation learning? Non-Euclidean geometries, particularly Riemannian manifolds such as hyperbolic (negative curvature) and spherical (positive curvature), offer powerful inductive biases for embedding complex graph structures like scale-free, hierarchical, and cyclic patterns. Meanwhile, spectral filtering excels at processing signal variations across graphs, making it effective in homophilic and heterophilic settings. Leveraging both can significantly enhance the learned representations. To this end, we propose Spectro-Riemannian Graph Neural Networks (CUSP) - the first graph representation learning paradigm that unifies both CUrvature (geometric) and SPectral insights. CUSP is a mixed-curvature spectral GNN that learns spectral filters to optimize node embeddings in products of constant curvature manifolds (hyperbolic, spherical, and Euclidean). Specifically, CUSP introduces three novel components: (a) Cusp Laplacian, an extension of the traditional graph Laplacian based on Ollivier-Ricci curvature, designed to capture the curvature signals better; (b) Cusp Filtering, which employs multiple Riemannian graph filters to obtain cues from various bands in the eigenspectrum; and (c) Cusp Pooling, a hierarchical attention mechanism combined with a curvature-based positional encoding to assess the relative importance of differently curved substructures in our graph. Empirical evaluation across eight homophilic and heterophilic datasets demonstrates the superiority of CUSP in node classification and link prediction tasks, with a gain of up to 5.3% over state-of-the-art models.
2024
- WWW
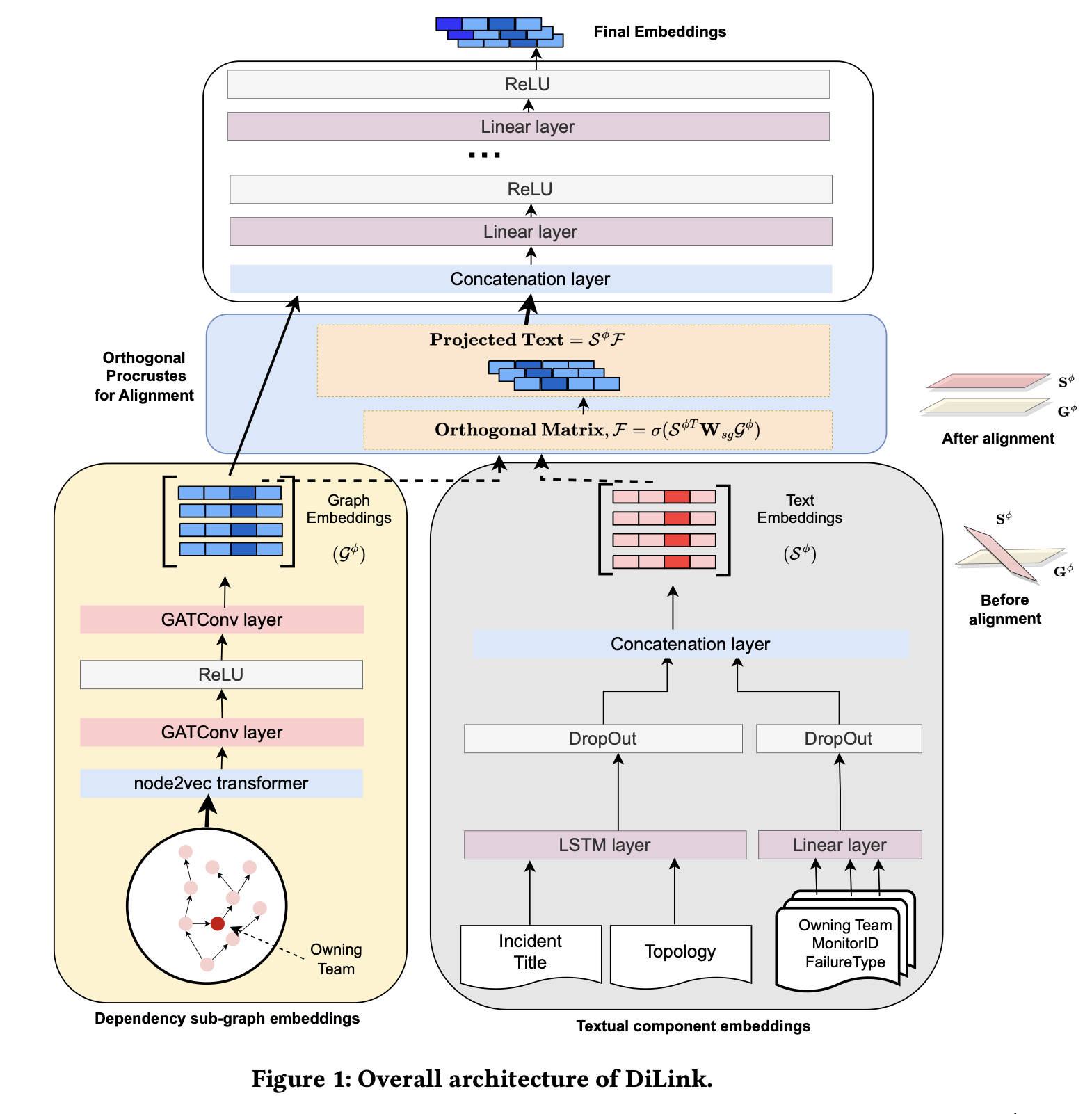 Dependency Aware Incident Linking in Large Cloud SystemsSupriyo Ghosh, Karish Grover, Jimmy Wong, Chetan Bansal, and 3 more authorsCompanion Proceedings of the ACM on Web Conference 2024
Dependency Aware Incident Linking in Large Cloud SystemsSupriyo Ghosh, Karish Grover, Jimmy Wong, Chetan Bansal, and 3 more authorsCompanion Proceedings of the ACM on Web Conference 2024Despite significant reliability efforts, large-scale cloud services inevitably experience production incidents that can significantly impact service availability and customer satisfaction. Worse, in many cases one incident can lead to multiple downstream failures due to cascading effects that create several related incidents across different dependent services. Often time On-call Engineers (OCEs) examine these incidents in silos that lead to significant amounts of manual effort and increase the overall time-to-mitigate incidents. Therefore, developing efficient incident linking models is of paramount importance for grouping related incidents into clusters so as to quickly resolve major outages and reduce on-call fatigue. Existing incident linking methods mostly leverage textual and contextual information of incidents (e.g., title, description, severity, impacted components), thus failing to leverage the inter-dependencies between services. In this paper, we propose the dependency-aware incident linking (DiLink) framework which leverages both textual and service dependency graph information to improve the accuracy and coverage of incident links not only emerge from same service, but also from different services and workloads. Furthermore, we propose a novel method to align the embeddings of multi-modal (i.e., textual and graphical) data using Orthogonal Procrustes. Extensive experimental results on real-world incidents from 5 workloads of Microsoft demonstrate that our alignment method has an F1-score of 0.96 (14% gain over current state-of-the-art methods). We are also in the process of deploying this solution across 610 services from these 5 workloads for continuously supporting OCEs improving incident management and reducing manual effort.
2022
- NeurIPS
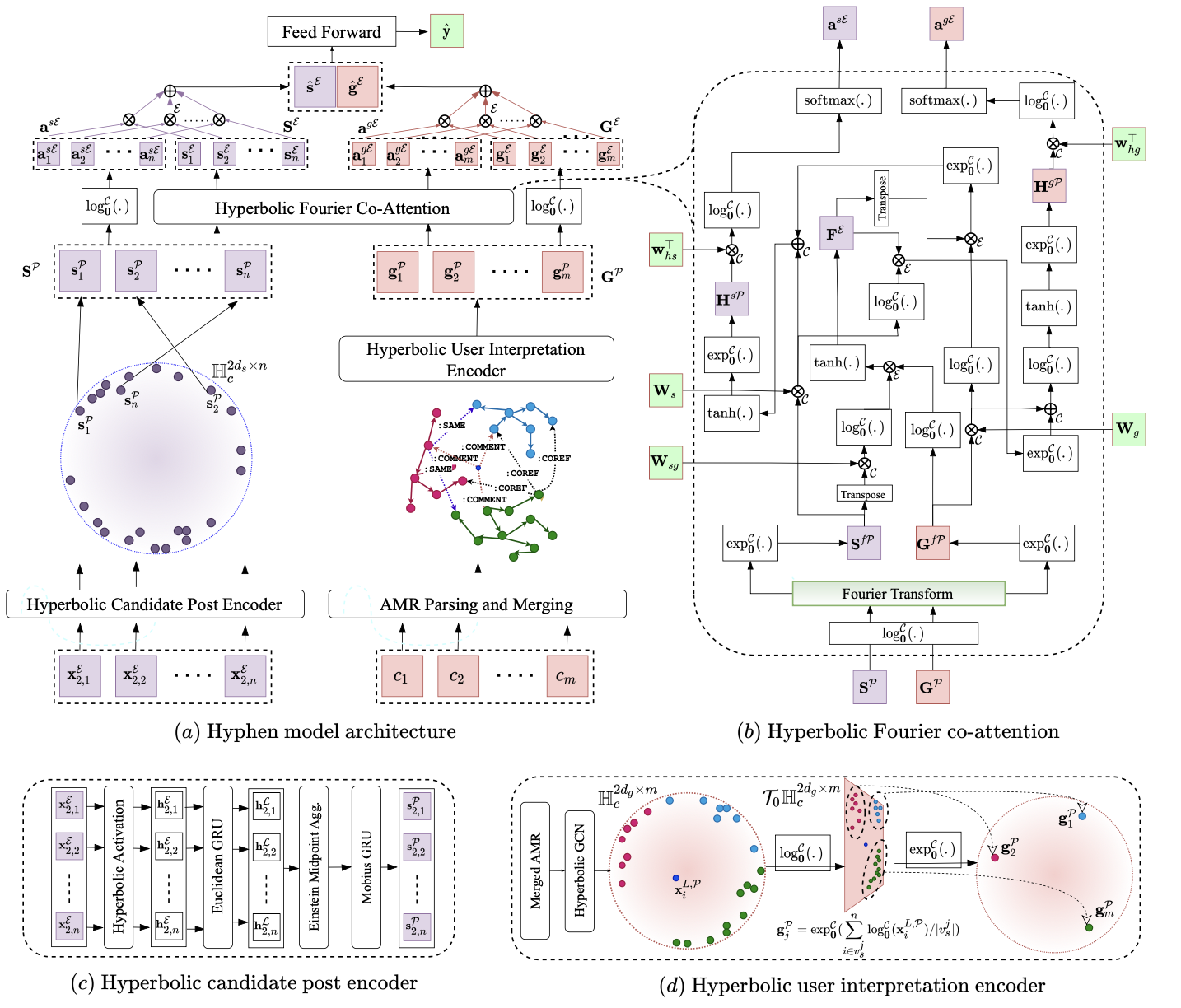 Public Wisdom Matters! Discourse-Aware Hyperbolic Fourier Co-Attention for Social-Text ClassificationKarish Grover, Phaneendra Angara, Md. Shad Akhtar, and Tanmoy ChakrabortyNeural Information Processing Systems Sep 2022
Public Wisdom Matters! Discourse-Aware Hyperbolic Fourier Co-Attention for Social-Text ClassificationKarish Grover, Phaneendra Angara, Md. Shad Akhtar, and Tanmoy ChakrabortyNeural Information Processing Systems Sep 2022Social media has become the fulcrum of all forms of communication. Classifying social texts such as fake news, rumour, sarcasm, etc. has gained significant attention. The surface-level signals expressed by a social-text itself may not be adequate for such tasks; therefore, recent methods attempted to incorporate other intrinsic signals such as user behavior and the underlying graph structure. Oftentimes, the "public wisdom" expressed through the comments/replies to a social-text acts as a surrogate of crowd-sourced view and may provide us with complementary signals. State-of-the-art methods on social-text classification tend to ignore such a rich hierarchical signal. Here, we propose Hyphen, a discourse-aware hyperbolic spec- tral co-attention network. Hyphen is a fusion of hyperbolic graph representation learning with a novel Fourier co-attention mechanism in an attempt to generalise the social-text classification tasks by incorporating public discourse. We parse public discourse as an Abstract Meaning Representation (AMR) graph and use the powerful hyperbolic geometric representation to model graphs with hierarchical structure. Finally, we equip it with a novel Fourier co-attention mechanism to capture the correlation between the source post and public discourse. Extensive experiments on four different social-text classification tasks, namely detecting fake news, hate speech, rumour, and sarcasm, show that Hyphen generalises well, and achieves state-of-the-art results on ten benchmark datasets. We also employ a sentence-level fact-checked and annotated dataset to evaluate how Hyphen is capable of producing explanations as analogous evidence to the final prediction.
- NAACL
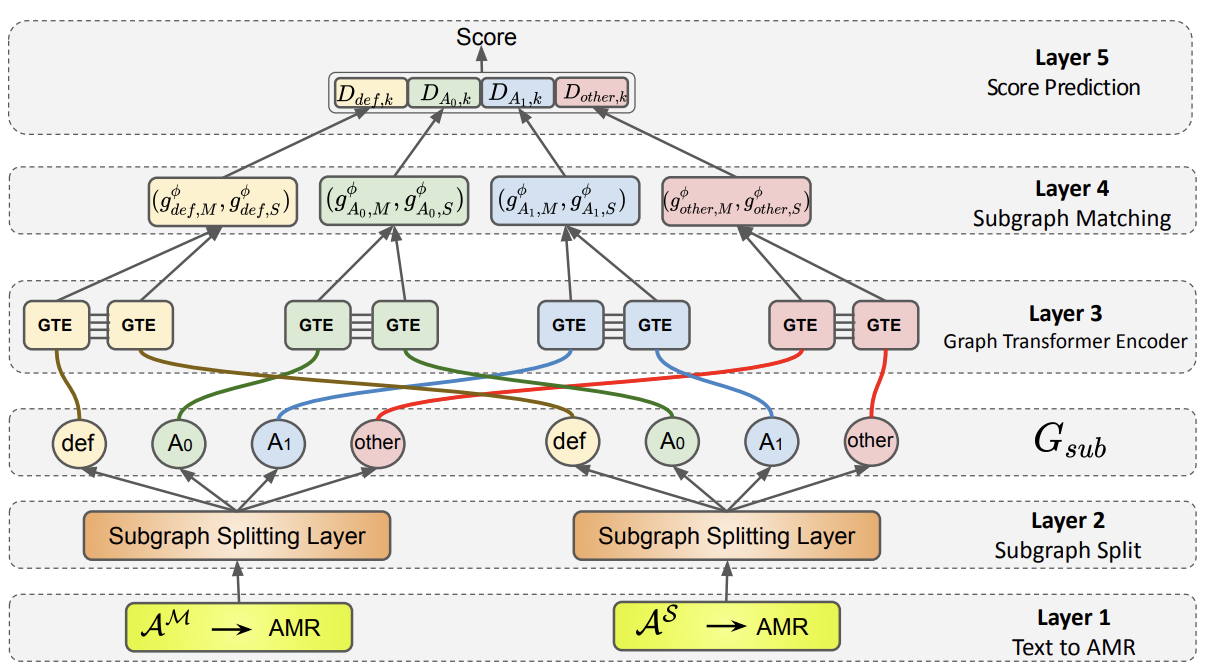 Multi-Relational Graph Transformer for Automatic Short Answer GradingRajat Agarwal, Varun Khurana, Karish Grover, Mukesh Mohania, and 1 more authorConference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Jul 2022
Multi-Relational Graph Transformer for Automatic Short Answer GradingRajat Agarwal, Varun Khurana, Karish Grover, Mukesh Mohania, and 1 more authorConference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Jul 2022The recent transition to the online educational domain has increased the need for Automatic Short Answer Grading (ASAG). ASAG automatically evaluates a student’s response against a (given) correct response and thus has been a prevalent semantic matching task. Most existing methods utilize sequential context to compare two sentences and ignore the structural context of the sentence; therefore, these methods may not result in the desired performance. In this paper, we overcome this problem by proposing a Multi-Relational Graph Transformer, MitiGaTe, to prepare token representations considering the structural context. Abstract Meaning Representation (AMR) graph is created by parsing the text response and then segregated into multiple subgraphs, each corresponding to a particular relationship in AMR. A Graph Transformer is used to prepare relation-specific token embeddings within each subgraph, then aggregated to obtain a subgraph representation. Finally, we compare the correct answer and the student response subgraph representations to yield a final score. Experimental results on Mohler’s dataset show that our system outperforms the existing state-of-the-art methods. We have released our implementation https://github.com/kvarun07/asag-gt, as we believe that our model can be useful for many future applications.
2021
- SEPLN
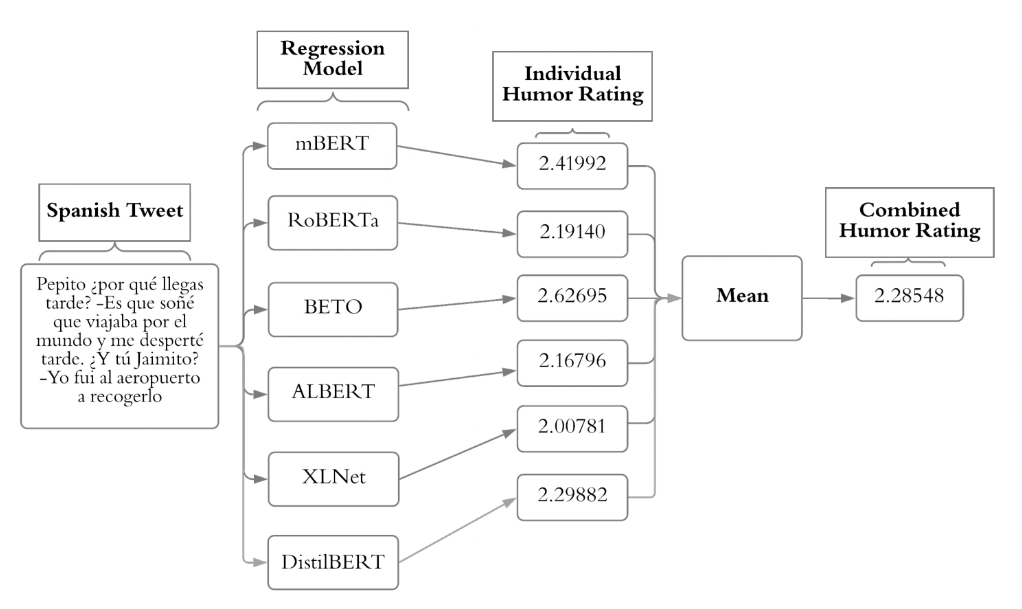 HAHA@ IberLEF: Humor Analysis using Ensembles of Simple Transformers.Karish Grover, and Tanishq GoelIberian Languages Evaluation Forum Jul 2021
HAHA@ IberLEF: Humor Analysis using Ensembles of Simple Transformers.Karish Grover, and Tanishq GoelIberian Languages Evaluation Forum Jul 2021This paper describes the system submitted to the Humor Analysis based on Human Annotation (HAHA) task at IberLEF 2021. This system achieves the winning F1 score of 0.8850 in the main task of binary classification (Task 1) utilizing an ensemble of a pre-trained multilingual BERT, pre-trained Spanish BERT (BETO), RoBERTa, and a naive Bayes classifier. We also achieve second place with macro F1 Scores of 0.2916 and 0.3578 in Multi-class Classification and Multi-label Classification tasks, respectively, and third place with an RMSE score of 0.6295 in the Regression task.